Projects
End-to-End LLM Development with RAG







 Project Link
Project Link
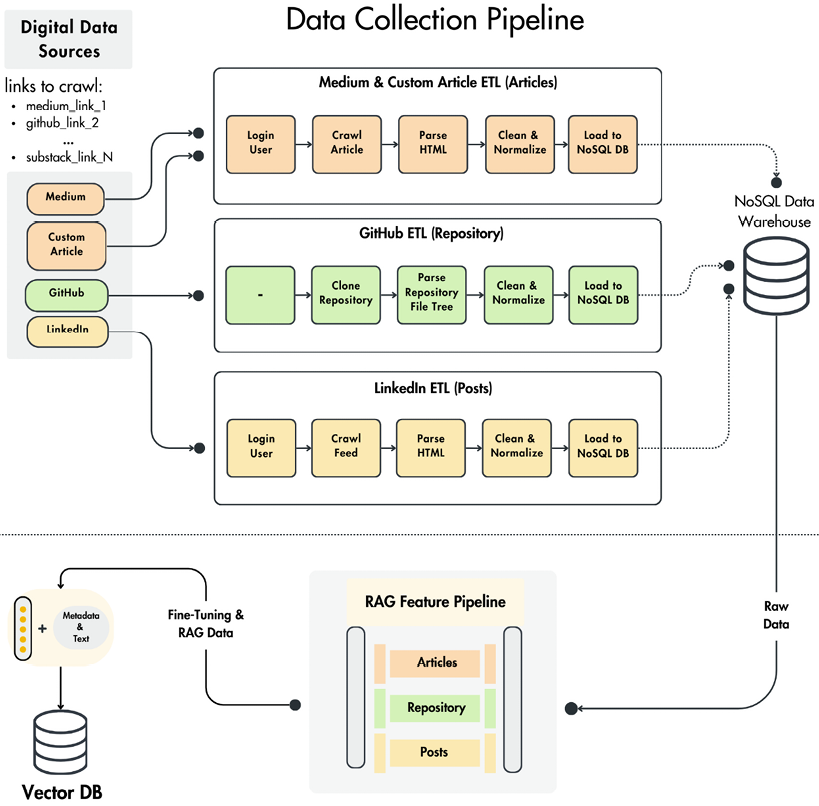
End-to-End LLM Development with RAG
- Built and deployed a domain-specific RAG system for ROS2 robotics, integrating MongoDB, Qdrant, and ClearML to automate ETL, feature engineering, and dataset generation pipelines, processing 10K+ repositories.
- Reduced training loss by 47% by fine-tuning Llama-3.2-3B with LoRA adapters on 27K+ domain-specific samples, combined with LangChain-based retrieval, reranking, and metadata extraction for precise query understanding.
- Optimized inference performance via quantization to GGUF format and deployment on AWS SageMaker with Docker, Ollama, and vLLM, achieving real-time streaming responses with sub-second latency.
- Built a Gradio web interface for live response streaming, semantic query expansion, and self-query metadata extraction, enabling accurate ROS2 navigation and motion planning guidance.
- Automated experiment tracking and evaluation with ClearML and GPT-4o-mini, supported by modular architecture, logging, and error handling for scalable deployments.
MLOps Pipeline for Chest X-Rays













 Project Link
Project Link
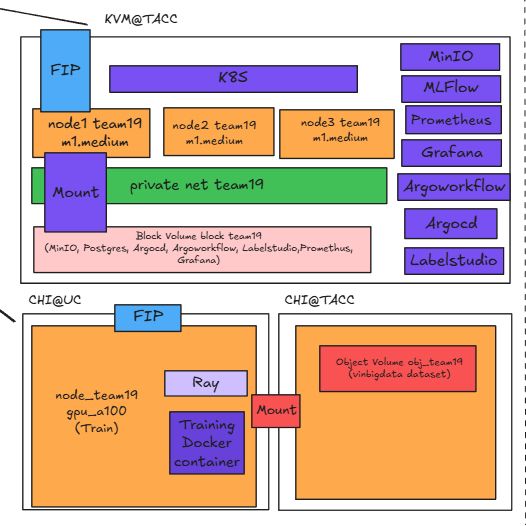
MLOps Pipeline for Chest X-Rays
- Architected distributed training pipeline with YOLO-12X (59.1M) on Ray + DDP, cutting training time by 65% on a 4-GPU cluster; automated hyperparameter tuning with Ray Tune and tracked experiments with MLflow.
- Designed scalable ETL + data quality pipeline for a 50GB multi-class X-ray dataset, converting annotations to YOLO format and visualizing distributions/heatmaps to ensure zero data leakage and address class imbalance.
- Deployed production ML platform on Kubernetes, managing microservices with ArgoCD/Helm; reduced infra setup time by 80% with Terraform + Ansible, and built CI/CD pipelines via Argo Workflows to cut deployment time.
- Optimized high-performance inference with Triton Inference Server + ONNX Runtime, achieving 0.52 mAP@50 with sub-20ms latency and 25 FPS throughput; exposed models via FastAPI APIs handling concurrent requests with dynamic batching.
- Implemented monitoring + feedback loops with Prometheus + Grafana, analyzing daily predictions for retraining, detecting data drift across statistical features, and tracking both system metrics and radiologist efficiency gains.

Soothify — AI Mental Health Companion




 Project Link
Project Link
Soothify — AI Mental Health Companion
- Architected a full-stack platform with Next.js, React, and TypeScript, integrating OpenAI Whisper STT/TTS and Hume.AI EVI for emotion-aware voice interactions via WebSocket streaming.
- Engineered a real-time voice pipeline with GPT-4o-mini backend and Hume AI emotion analysis, using MongoDB for assessment tracking and user analytics.
- Developed emotion-responsive chat system with conversation history and severity-based resource routing, enabling personalized mental health discussions.
- Built a wellness ecosystem combining interactive tools, MongoDB-powered progress tracking, and AI-driven recommendations, supporting 4 assessment types.
- Implemented scalable voice infrastructure with WebSocket relay servers, maintaining 99% uptime while handling 5 concurrent sessions through connection pooling and error recovery.
PhishLearn — Enterprise Phishing Awareness Platform






 Project Link
Project Link
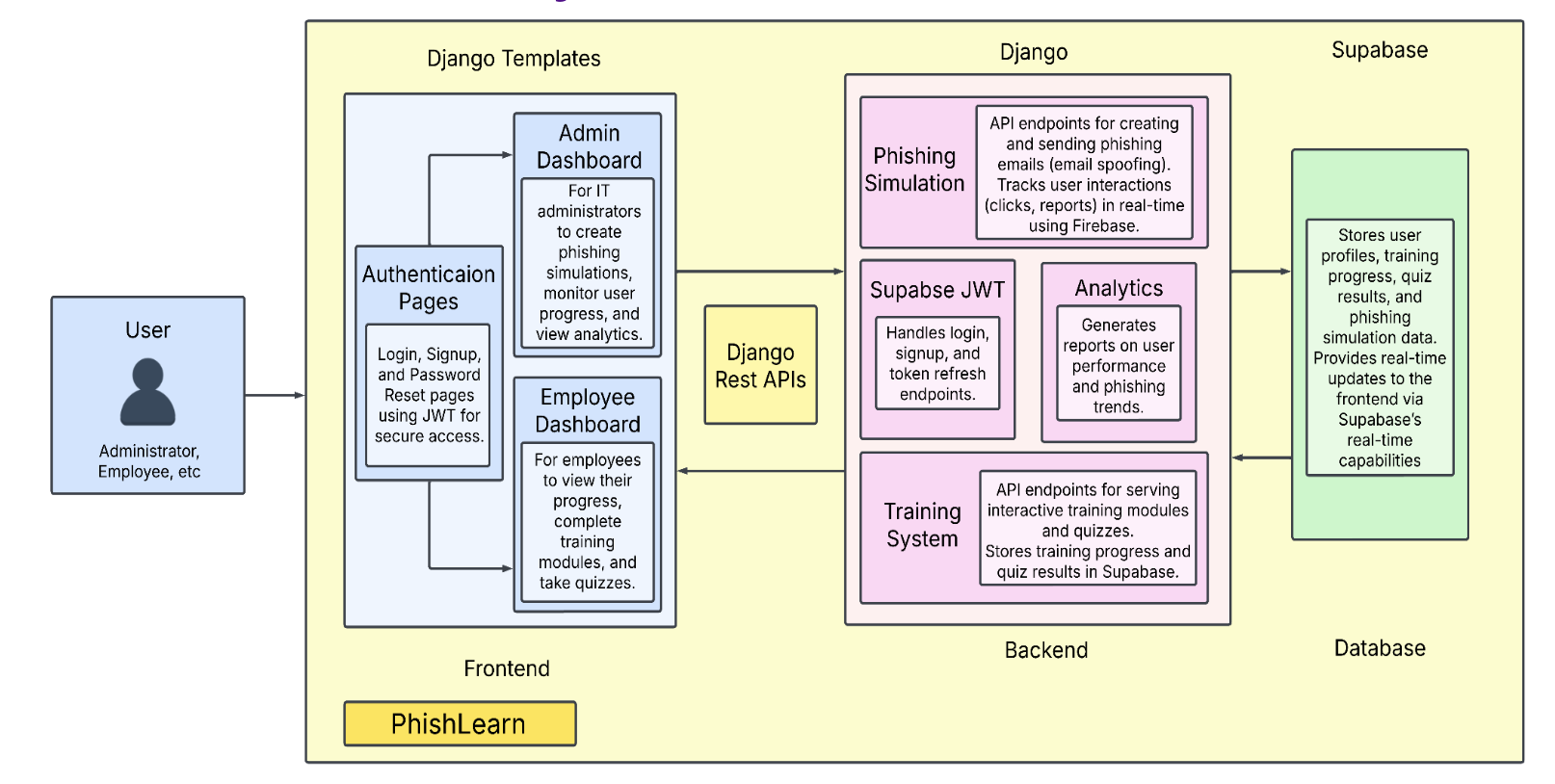
PhishLearn — Enterprise Phishing Awareness Platform
- Engineered a full-stack phishing awareness platform with Django REST Framework, PostgreSQL (Supabase), and Gophish integration, enabling organizations to run scalable campaigns for 100+ users.
- Built a phishing simulation and adaptive training system, generating realistic attack scenarios and triggering personalized courses/quizzes.
- Developed real-time analytics dashboards and monitoring systems, tracking metrics (opens, clicks, credential submissions) and authentication events (browser/IP fingerprinting) to provide insights and threat detection.
- Implemented containerized deployments with Docker and AWS EC2, orchestrating multi-service environments via automated CI/CD pipelines, and added backend unit tests (pytest, coverage) to ensure reliable releases.
- Designed and optimized database schemas and REST endpoints for campaign/user management, and delivered a responsive frontend using Bootstrap, HTML/CSS, JS for training and analytics views.
Git Issue Bot

 Project Link
Project Link
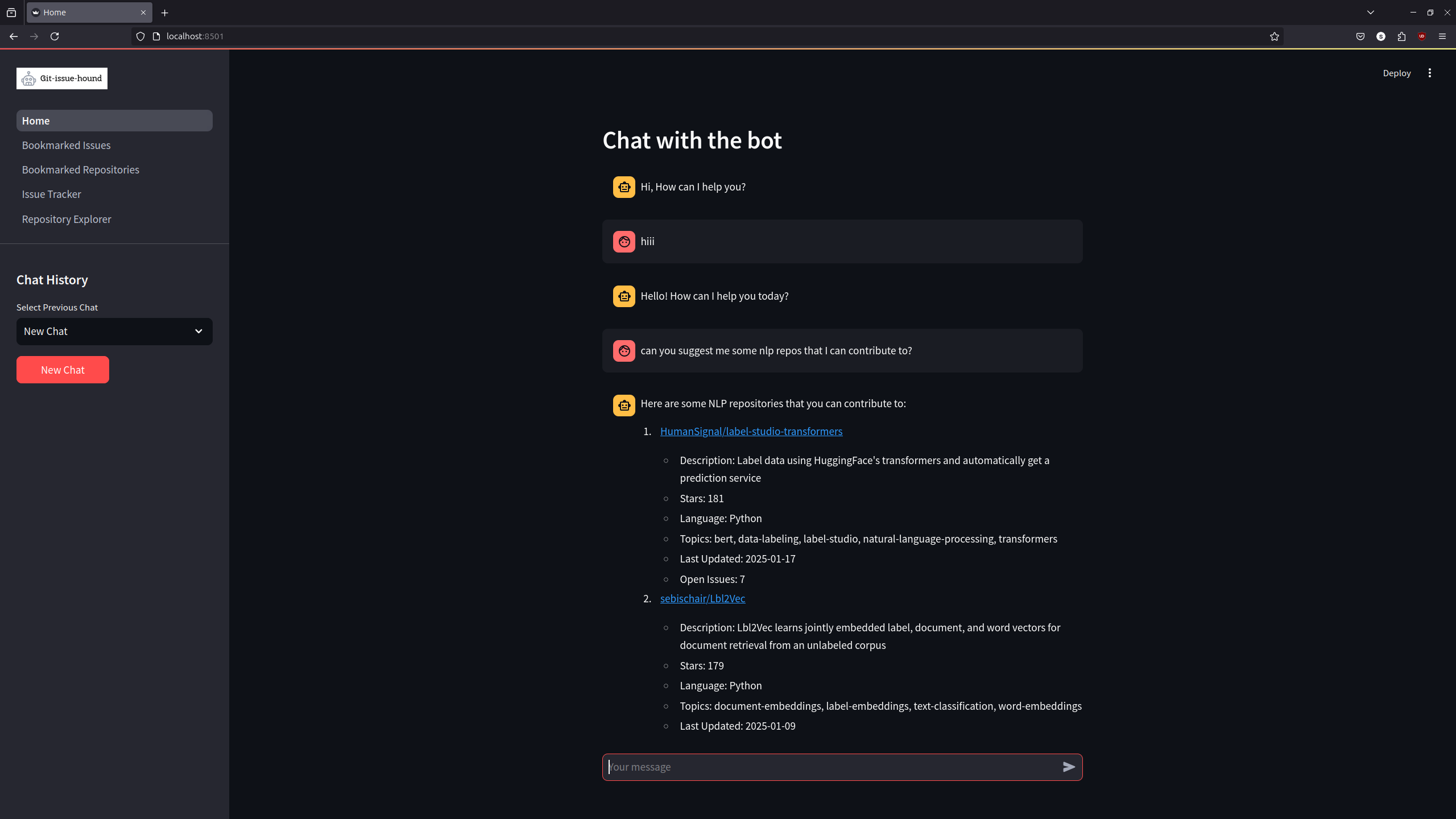
Git Issue Bot
- Engineered a full-stack AI application using Python, Streamlit, LangChain, and PostgreSQL, implementing multi-page UI, database persistence, and conversation memory for GitHub issue discovery and bookmarking.
- Integrated 6+ external APIs (GitHub, OpenAI, DuckDuckGo, StackExchange, Wikidata) by building custom LangChain tools with authentication, rate-limit handling, and structured query logic.
- Improved query speed by 70% by designing optimized PostgreSQL schema with indexing, connection pooling, and caching, cutting latency and enabling real-time search.
- Streamlined deployment with Docker Compose multi-stage builds and environment-based configs.
- Applied modular architecture and best practices using Pydantic models, type hints, exception classes, and reusable LangChain BaseTool components for scalability and maintainability.